Hallo Leute,
folgende Gegebenheiten:
Ein Schädlingsbekämpfer betreut Kunden. Jeder Kunde hat eine gewisse Anzahl an Schädlings-Fallen bei sich stehen. Es gibt 3 Typen von Fallen, die alle unterschiedliche Attribute haben.
Beim Kontrollgang vor Ort wird zu jeder Falle des Kunden das Datum und ein Befund (=befüllen der Falllenattribute) vermerkt.
Bsp:
Als Kern-Entities betrachte ich die Fallentypen, die ich per FK Constraint einer Firma zuordne.
Jetzt bräuchte ich Denkanstöße wie ich die Fallen-Liste verwalten könnte, bzw. ob meine Vorgehensweise so überhaupt sin ergibt.
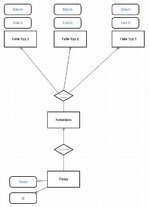
Anbei auch ein Versuch eines ER Diagrams.
Danke für Eure Hilfe!
LG
folgende Gegebenheiten:
Ein Schädlingsbekämpfer betreut Kunden. Jeder Kunde hat eine gewisse Anzahl an Schädlings-Fallen bei sich stehen. Es gibt 3 Typen von Fallen, die alle unterschiedliche Attribute haben.
Beim Kontrollgang vor Ort wird zu jeder Falle des Kunden das Datum und ein Befund (=befüllen der Falllenattribute) vermerkt.
Bsp:
- Am 14.10.2014 wird bei Firma ACME eine Falle vom Typ A befundet, 3 von Typ B und 2 von Typ C
- Am 21.10.2014 wird bei Firma ACME eine Falle vom Typ A befundet, 3 von Typ B und 2 von Typ C
- Am 21.10.2014 wird bei Firma XYZ 3 Fallen vom Typ A befundet, 1 von Typ B und 4 von Typ C
Als Kern-Entities betrachte ich die Fallentypen, die ich per FK Constraint einer Firma zuordne.
Jetzt bräuchte ich Denkanstöße wie ich die Fallen-Liste verwalten könnte, bzw. ob meine Vorgehensweise so überhaupt sin ergibt.
Anbei auch ein Versuch eines ER Diagrams.
Danke für Eure Hilfe!
LG