Hallo zusammen,
ich habe eine Frage, die verschiedene Abfragen verknüpft. Im Vornherein möchte ich schon mal sagen, dass mein MySQL Wissen begrenzt ist. Im Rahmen meiner Masterarbeit habe ich probiert so gut es ging mir etwas über MySQl selbst beizubringen. Jedoch komme ich bei dem folgenden Problem nicht weiter.
Es geht dabei darum, dass ich über den Beobachtungszeitraum (2006,2008,2010,2012,2013) Fachabteilungen mit ihren ärztlichen Fachexpertisen vergleichen möchte. Dadurch möchte ich herausfinden, ob sich die ärztliche Fachexpertise über die Jahre verändert.
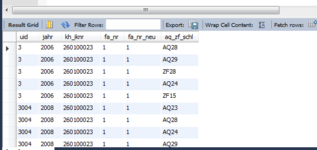
Hierfür habe ich eine Tabelle mit den folgenden Einträgen (siehe auch angehängtes Bild):
- uid: identifiziert ein Krankenhaus (iknr) für ein bestimmtes Jahr
- jahr: Beobachtungszeiträume [2006,2008,2010,2012,2013]
- kh_iknr: Instiutionskennzeichnung. Jedes Krankenhaus besitzt eine eindeutig zugeordnete Nummer (verändert sich nicht über die Jahre).
- fa_nr: Fachabteilungsnummer nicht geordnet
- fa_nr_neu: Fachabteilungsnummer geordnet. Sodas die Fachabteilungsnummer über die Jahre konsistent ist.
- aq_zf_schl: ärztliche Fachexpertise. Jede Abteilung hat eine Menge von Schlüsseln, die die Fachexpertise wiedergint.
Mit der Abfrage möchte ich folgendes erreichen (nur eine Idee):
1) starten mit dem Vergleich von zwei aufeinanderfolgenden Betrachtungszeiträumen 2006 und 2008
2) wähle das erste Krankenhaus aus der Liste
3) nehme die erste Fachabteilung
4) gucke dir die ärztliche Fachexpertise aus dem Jahr 2006 an
5) und vergleiche sie mit der ärztlichen Fachexpertise aus dem Jahr 2008
6) zähle die neu dazugekommenen Schlüssel (aq_zf_schl)
7) nehme die nächste Fachabteilung und führe die Schritt (4-6) nochmals durch [dies wiederhole so lange, bis keine Fachabteilungen mehr über sind]
8) Wenn es keine Fachabteilungen mehr gibt, nehme das nächste Krankenhaus und gehe die Schritte (3-7 durch)
9) Wenn alle Krankenhäuser für den Beobachtungszeitraum abgearbeitet sind, dann springe in den nächsten (2008 und 2010) und wiederhole die Schritte (2-8)
Bei der Tabelle ist noch folgendes zu beachten:
- Die Fachabteilungsnummern sind nicht immer durchgehende nummeriert, wie z.B. 1,2,3,4,5,6,7,8 es kann auch vorkommen, dass manche Fachabteilungsnummern nicht vergeben sind z.B. 1,2,3,7,8,12,13,17. Es kann auch passieren, dass nicht mit der Nummer 1 gestartet wird. Fachabteilungsnummern können nur in den Bereichen 1 bis 98 vorkommen. Die Zahl 99 bedeutet, dass keine Zuordnung stattgefunden hat. Dieses darf nicht mit berücksichtig werden. Der Code müsste somit immer die Zahlen 1 bis 98 durchlaufen und dann abbrechen und zum nächsten Krankenhaus wechseln.
- Bei den Jahren ist zu berücksichtigen, dass manche Fachabteilungen nicht in jedem Betrachtungszeitraum auftauchen. Es kann z.B. so etwas passieren:
o Fa_nr_neu 3 = 2006,2008 und 2012,2013 oder
o Fa_nr_neu 5 = 2010,2012,2013
- Hier weiß ich leider noch nicht, wie man das berücksichtigen könnte. Vielleicht teilt man die Ausgangstabelle in 5 Hilfstabellen, für jedes Jahr eine, und führt dann die Abfragen durch. So das z.B. erstmal der Fall der Veränderungen in den Fachexpertisen vom Jahr 2006 auf das Jahr 2008 untersucht wird und dann 2008 auf 2010 usw.
Ich habe mit dem Code schon mal für einen konkreten Fall angefangen.
SELECT uid, jahr, kh_iknr, fa_nr_neu, count(aq_zf_schl) as Inno_1 FROM quali.kh_fa_afe WHERE (
aq_zf_schl NOT IN(
SELECT aq_zf_schl FROM quali.kh_fa_afe WHERE jahr = 2006 AND kh_iknr = 260100023 AND fa_nr_neu =1
)
AND jahr = 2008 AND kh_iknr = 260100023 AND fa_nr_neu =1
)
Als Ergebnis sollte ein Code rauskommem, der die komplette Tabelle durchläuft, und für jede Fachabteilung eine neue Spalte hinzufügt, in der gezählt wird, ob neue ärztliche Fachexpertise dazugekommen ist und wie viel.
Ich hoffe ich konnte mein Problem einigermaßen vernünftig schildern. Falls ihr noch mehr Informationen benötigt, dann probiere ich mein Problem noch genauer oder anders zu beschreiben.
ich habe eine Frage, die verschiedene Abfragen verknüpft. Im Vornherein möchte ich schon mal sagen, dass mein MySQL Wissen begrenzt ist. Im Rahmen meiner Masterarbeit habe ich probiert so gut es ging mir etwas über MySQl selbst beizubringen. Jedoch komme ich bei dem folgenden Problem nicht weiter.
Es geht dabei darum, dass ich über den Beobachtungszeitraum (2006,2008,2010,2012,2013) Fachabteilungen mit ihren ärztlichen Fachexpertisen vergleichen möchte. Dadurch möchte ich herausfinden, ob sich die ärztliche Fachexpertise über die Jahre verändert.
Hierfür habe ich eine Tabelle mit den folgenden Einträgen (siehe auch angehängtes Bild):
- uid: identifiziert ein Krankenhaus (iknr) für ein bestimmtes Jahr
- jahr: Beobachtungszeiträume [2006,2008,2010,2012,2013]
- kh_iknr: Instiutionskennzeichnung. Jedes Krankenhaus besitzt eine eindeutig zugeordnete Nummer (verändert sich nicht über die Jahre).
- fa_nr: Fachabteilungsnummer nicht geordnet
- fa_nr_neu: Fachabteilungsnummer geordnet. Sodas die Fachabteilungsnummer über die Jahre konsistent ist.
- aq_zf_schl: ärztliche Fachexpertise. Jede Abteilung hat eine Menge von Schlüsseln, die die Fachexpertise wiedergint.
Mit der Abfrage möchte ich folgendes erreichen (nur eine Idee):
1) starten mit dem Vergleich von zwei aufeinanderfolgenden Betrachtungszeiträumen 2006 und 2008
2) wähle das erste Krankenhaus aus der Liste
3) nehme die erste Fachabteilung
4) gucke dir die ärztliche Fachexpertise aus dem Jahr 2006 an
5) und vergleiche sie mit der ärztlichen Fachexpertise aus dem Jahr 2008
6) zähle die neu dazugekommenen Schlüssel (aq_zf_schl)
7) nehme die nächste Fachabteilung und führe die Schritt (4-6) nochmals durch [dies wiederhole so lange, bis keine Fachabteilungen mehr über sind]
8) Wenn es keine Fachabteilungen mehr gibt, nehme das nächste Krankenhaus und gehe die Schritte (3-7 durch)
9) Wenn alle Krankenhäuser für den Beobachtungszeitraum abgearbeitet sind, dann springe in den nächsten (2008 und 2010) und wiederhole die Schritte (2-8)
Bei der Tabelle ist noch folgendes zu beachten:
- Die Fachabteilungsnummern sind nicht immer durchgehende nummeriert, wie z.B. 1,2,3,4,5,6,7,8 es kann auch vorkommen, dass manche Fachabteilungsnummern nicht vergeben sind z.B. 1,2,3,7,8,12,13,17. Es kann auch passieren, dass nicht mit der Nummer 1 gestartet wird. Fachabteilungsnummern können nur in den Bereichen 1 bis 98 vorkommen. Die Zahl 99 bedeutet, dass keine Zuordnung stattgefunden hat. Dieses darf nicht mit berücksichtig werden. Der Code müsste somit immer die Zahlen 1 bis 98 durchlaufen und dann abbrechen und zum nächsten Krankenhaus wechseln.
- Bei den Jahren ist zu berücksichtigen, dass manche Fachabteilungen nicht in jedem Betrachtungszeitraum auftauchen. Es kann z.B. so etwas passieren:
o Fa_nr_neu 3 = 2006,2008 und 2012,2013 oder
o Fa_nr_neu 5 = 2010,2012,2013
- Hier weiß ich leider noch nicht, wie man das berücksichtigen könnte. Vielleicht teilt man die Ausgangstabelle in 5 Hilfstabellen, für jedes Jahr eine, und führt dann die Abfragen durch. So das z.B. erstmal der Fall der Veränderungen in den Fachexpertisen vom Jahr 2006 auf das Jahr 2008 untersucht wird und dann 2008 auf 2010 usw.
Ich habe mit dem Code schon mal für einen konkreten Fall angefangen.
SELECT uid, jahr, kh_iknr, fa_nr_neu, count(aq_zf_schl) as Inno_1 FROM quali.kh_fa_afe WHERE (
aq_zf_schl NOT IN(
SELECT aq_zf_schl FROM quali.kh_fa_afe WHERE jahr = 2006 AND kh_iknr = 260100023 AND fa_nr_neu =1
)
AND jahr = 2008 AND kh_iknr = 260100023 AND fa_nr_neu =1
)
Als Ergebnis sollte ein Code rauskommem, der die komplette Tabelle durchläuft, und für jede Fachabteilung eine neue Spalte hinzufügt, in der gezählt wird, ob neue ärztliche Fachexpertise dazugekommen ist und wie viel.
Ich hoffe ich konnte mein Problem einigermaßen vernünftig schildern. Falls ihr noch mehr Informationen benötigt, dann probiere ich mein Problem noch genauer oder anders zu beschreiben.
")
