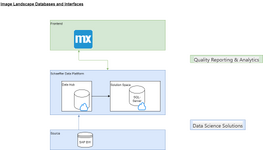
Hallo zusammen,
ich bin recht neu beim Thema SQL und habe ein Problem beim gruppieren.
Folgender SQL funktioniert wie gewünscht:
Select sum(rt1.erlöse)
From Vertrag v
Inner Join Rechnung1 r1 on v.id1 = r1.id1
Inner Join Rechnungsteil rt1 on r1.id2 = rt1.id2
Group by v.nummer
Nun möchte ich mir aus einer weiteren Rechnungstabelle ebenfalls die Summe der Erlöse je Vertrag anzeigen lassen. Wenn ich aber folgendes hinzufügen:
Inner Join Rechnung2 r2 on v.id3 = r2.id3
Dann ist die Summe von rt1.erlöse um ein vielfacher höher als vorher (und zwar um die Anzahl der Datensätze aus Tabelle r2).
Wieso ist das so und wie kann ich das verhindern?
Besten Dank vorab für eure Hilfe!
VG
ich bin recht neu beim Thema SQL und habe ein Problem beim gruppieren.
Folgender SQL funktioniert wie gewünscht:
Select sum(rt1.erlöse)
From Vertrag v
Inner Join Rechnung1 r1 on v.id1 = r1.id1
Inner Join Rechnungsteil rt1 on r1.id2 = rt1.id2
Group by v.nummer
Nun möchte ich mir aus einer weiteren Rechnungstabelle ebenfalls die Summe der Erlöse je Vertrag anzeigen lassen. Wenn ich aber folgendes hinzufügen:
Inner Join Rechnung2 r2 on v.id3 = r2.id3
Dann ist die Summe von rt1.erlöse um ein vielfacher höher als vorher (und zwar um die Anzahl der Datensätze aus Tabelle r2).
Wieso ist das so und wie kann ich das verhindern?
Besten Dank vorab für eure Hilfe!
VG
Zuletzt bearbeitet: