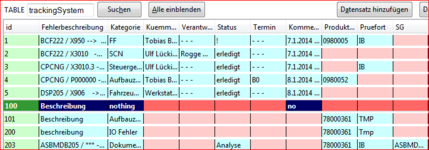
Hallo Liebes Forumteam,
ich habe eine sqlite Datenbank. Ich habe da auch mehrere identische Zeilen, die ich natürlich nur 1 Mal ausgeben möchte. Ich schreibe:
SELECT * FROM t GROUP BY NAME(wo ich die doppelte Zeilen nur 1 mal ausgeben möchte)
funktioniert super!!!
Das Problem besteht darin, wenn ich meine Datensätze noch ein mal in die DB importiere, bekommen die entsprechend andere id(primary key i++ bei mir) == Zeilennummer (bei mir) und wenn ich meine SELECT Statement noch ein mal starte, sehe ich die Zeilen natürlich nur 1 Mal, aber mit einer anderen id Nummer. Dummerweise werden da die zu letzt importierte angezeigt(also die höchste Nummer). Ich möchte nur eine einzige Zeile aus der DB immer anzeigen.
Was kann ich noch tun?
Vielen Dank erstmal im Voraus
Daniel
ich habe eine sqlite Datenbank. Ich habe da auch mehrere identische Zeilen, die ich natürlich nur 1 Mal ausgeben möchte. Ich schreibe:
SELECT * FROM t GROUP BY NAME(wo ich die doppelte Zeilen nur 1 mal ausgeben möchte)
funktioniert super!!!
Das Problem besteht darin, wenn ich meine Datensätze noch ein mal in die DB importiere, bekommen die entsprechend andere id(primary key i++ bei mir) == Zeilennummer (bei mir) und wenn ich meine SELECT Statement noch ein mal starte, sehe ich die Zeilen natürlich nur 1 Mal, aber mit einer anderen id Nummer. Dummerweise werden da die zu letzt importierte angezeigt(also die höchste Nummer). Ich möchte nur eine einzige Zeile aus der DB immer anzeigen.
Was kann ich noch tun?
Vielen Dank erstmal im Voraus
Daniel
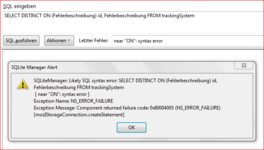
")
")