AchimOnBike
Neuer Benutzer
- Beiträge
- 3
Hallo in die Runde ")
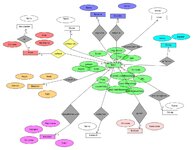
ich bin grad dabei, meine erste Datenbank zu erstellen. Ich habe gras wieder ein Bücherregal gebaut... aber das macht es auch nicht einfacher Mit base von open office möchte ich da Ordnung reinbringen. Ich hab schon etwas gegooglt und mir videos angeschaut und eine Entity Relation erstellt, die ich mal angehängt habe. Da sind auch noch ein paar Fragen.
Ich will meine Bücher nicht groß ausleihen, aber es geht doch ab und zu mal eines an nen Freund oder ich leihe mir eines aus. Da bietet es sich an, das hier auch eizutragen.
Braucht man da verschiedene Tabellen für verliehen_an, ausgeliehen_von, Besitzer (oder impliziert hier bei der dritten Tabelle schon das _an und _von, den Besitzer?)
Eine weitere Namestabelle wäre dann die, der Autoren.
Bei alle gemeinsam stellen sich mir jetzt die Frage (dieses threads) ob ich aus einer Tabelle zB Autor nicht zweie machen sollte: AutorVorname und AutorNachname, da es bei meinen Büchern einen Dan Brown und einen Dan Abnett gibt und bei den Nachnamen 3x einen Beckett.
so, erst mal genug geschrieben. Bin gespannt auf Antworten
Gruß Achim
ich bin grad dabei, meine erste Datenbank zu erstellen. Ich habe gras wieder ein Bücherregal gebaut... aber das macht es auch nicht einfacher
Mit base von open office möchte ich da Ordnung reinbringen. Ich hab schon etwas gegooglt und mir videos angeschaut und eine Entity Relation erstellt, die ich mal angehängt habe. Da sind auch noch ein paar Fragen.Ich will meine Bücher nicht groß ausleihen, aber es geht doch ab und zu mal eines an nen Freund oder ich leihe mir eines aus. Da bietet es sich an, das hier auch eizutragen.
Braucht man da verschiedene Tabellen für verliehen_an, ausgeliehen_von, Besitzer (oder impliziert hier bei der dritten Tabelle schon das _an und _von, den Besitzer?)
Eine weitere Namestabelle wäre dann die, der Autoren.
Bei alle gemeinsam stellen sich mir jetzt die Frage (dieses threads) ob ich aus einer Tabelle zB Autor nicht zweie machen sollte: AutorVorname und AutorNachname, da es bei meinen Büchern einen Dan Brown und einen Dan Abnett gibt und bei den Nachnamen 3x einen Beckett.
so, erst mal genug geschrieben. Bin gespannt auf Antworten
Gruß Achim