Hallo Leute,
ich hab ein kleines Programm geschrieben um die Bestellabwicklung für unsere IT etwas zu vereinfachen.
Hierfür hab ich eine Datenbank unter Sql mit der ich mehrere Tabellen fülle.
Ich habe für jeden Gerätetyp eine eigene Tabelle erstellt, da nicht jedes Gerät die volle Anzah der Spalten benötigt:
für die Tabellen Rechner, Monitore, NC und Bestellungen habe ich mit eineigen Abweichungen unten genanntes Schema verfolgt:
Name|Benutzer|Verschiedene Liefer und Bestelldaten|.....|Gerätedaten|HandelswareGuid
Bestimmte wiederkehrende Daten wie Hersteller und modelle habe ich schon über Normalisierung in untertabellen verfrachtet.
Der Name der geräte ist immer auch der Jeweilige primärschlüssel der Tabellen.
Also lt001,lt002 usw.
Nun wollte ich eine weitere Tabelle Handelsware einfügen in der Geräte landen, welch nicht sofort einem User zugeordnet werden .
Beim Umbuchen eines Gerätes auf die Handelsware lasse ich in den jewiligen Tabellen bei dem betroffenen Gerät eine Guid im Feld Handelsware erstellen, welche dann auch Primärschlüssel der Tabelle Handelsware ist.
Hier stehen dann weitere Informationen wie Preis und Belegnummer.
Beim ausbuchen aus der Handelsware fehlt mir aber eine Möglichkeit von der Guid aus auf die richtige Tabelle zu schließen, weil Sie ja in einer der 4 Tabellen versteckt ist.
Bisher helfe ich mir damit das ich in der Handelswaretabelle eine weiter Spalte einfüge in der ich die
passende Tabelle als String abspeichere. Diese Frage ich dann vor dem eigentlichen Update programmiertechnisch ab.
Ich will mein programm aber in zukunfz immer mal wieder erweitern, und würde so ein update dann gerne über 1 einziges Sql-Statement machen da das Programm und der Aufbau wahrscheinlich sonst zu umständlich wird.
Habe ich beim Datenbankdesign einen Fehler gemacht?
Muss ich die Tabellen in irgendeiner weise in Beziehung zu einander setzen?
Ich bin bereit die ganze Datenbank nocheinmal von vorne zu erstellen, Hauptsache sie bleibt skalierbar!
Besten Dank im Voraus
ich hab ein kleines Programm geschrieben um die Bestellabwicklung für unsere IT etwas zu vereinfachen.
Hierfür hab ich eine Datenbank unter Sql mit der ich mehrere Tabellen fülle.
Ich habe für jeden Gerätetyp eine eigene Tabelle erstellt, da nicht jedes Gerät die volle Anzah der Spalten benötigt:
für die Tabellen Rechner, Monitore, NC und Bestellungen habe ich mit eineigen Abweichungen unten genanntes Schema verfolgt:
Name|Benutzer|Verschiedene Liefer und Bestelldaten|.....|Gerätedaten|HandelswareGuid
Bestimmte wiederkehrende Daten wie Hersteller und modelle habe ich schon über Normalisierung in untertabellen verfrachtet.
Der Name der geräte ist immer auch der Jeweilige primärschlüssel der Tabellen.
Also lt001,lt002 usw.
Nun wollte ich eine weitere Tabelle Handelsware einfügen in der Geräte landen, welch nicht sofort einem User zugeordnet werden .
Beim Umbuchen eines Gerätes auf die Handelsware lasse ich in den jewiligen Tabellen bei dem betroffenen Gerät eine Guid im Feld Handelsware erstellen, welche dann auch Primärschlüssel der Tabelle Handelsware ist.
Hier stehen dann weitere Informationen wie Preis und Belegnummer.
Beim ausbuchen aus der Handelsware fehlt mir aber eine Möglichkeit von der Guid aus auf die richtige Tabelle zu schließen, weil Sie ja in einer der 4 Tabellen versteckt ist.
Bisher helfe ich mir damit das ich in der Handelswaretabelle eine weiter Spalte einfüge in der ich die
passende Tabelle als String abspeichere. Diese Frage ich dann vor dem eigentlichen Update programmiertechnisch ab.
Ich will mein programm aber in zukunfz immer mal wieder erweitern, und würde so ein update dann gerne über 1 einziges Sql-Statement machen da das Programm und der Aufbau wahrscheinlich sonst zu umständlich wird.
Habe ich beim Datenbankdesign einen Fehler gemacht?
Muss ich die Tabellen in irgendeiner weise in Beziehung zu einander setzen?
Ich bin bereit die ganze Datenbank nocheinmal von vorne zu erstellen, Hauptsache sie bleibt skalierbar!
Besten Dank im Voraus
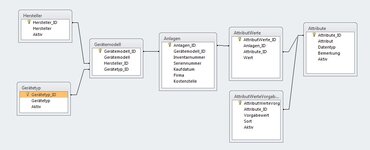
") Hier kann man aber auch den Schritt zurück gehen und einfach die eine Atribute Tabelle in mehrere Aufteilen, eine für CHAR, eine für INT, eine für DATETIME, etc. In jedem Fall erreicht man damit eine enorme Flexibilität was die Abbildung von unterschiedlichen Objekten angeht.
Hier kann man aber auch den Schritt zurück gehen und einfach die eine Atribute Tabelle in mehrere Aufteilen, eine für CHAR, eine für INT, eine für DATETIME, etc. In jedem Fall erreicht man damit eine enorme Flexibilität was die Abbildung von unterschiedlichen Objekten angeht.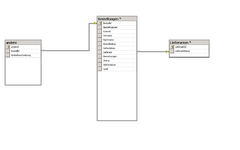

") ) . Wir geben ja nur gut gemeinte Tipps. Was Du davon nachher wirklich brauchen kannst, hängt ja in erster Linie von den Anforderungen Deines Projekts ab. Mit unseren Tipps hoffen wir Dir nur soweit helfen zu können, dass du nachher nicht in eine echte Problem-Falle läufst.
) . Wir geben ja nur gut gemeinte Tipps. Was Du davon nachher wirklich brauchen kannst, hängt ja in erster Linie von den Anforderungen Deines Projekts ab. Mit unseren Tipps hoffen wir Dir nur soweit helfen zu können, dass du nachher nicht in eine echte Problem-Falle läufst.