Guten Morgen,
ich möchte die Dauer eines gesetzten Status berechnen, schaffe das aber leider nicht.
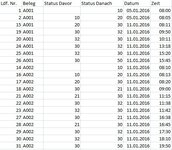
Ein Beispiel der Tabelle ist angehängt.
Ich muss also z.B. berechnen, wie lange der Status "20" gesetzt war. Dies ist für Beleg "A001" vom 05.01.2016 08:05 bis 08.01.2016 08:11 der Fall - soweit auch kein Problem.
Nun sollte ich aber nur die Arbeitszeit (zB 08-17 Uhr) an Arbeitstagen (also ohne SA/SO/Feiertag) für die Berechnung berücksichtigen - und dabei scheitere ich leider.
D.h. das erwünschte Ergebnis wäre "2166 Minuten".
MS SQL Server 2012 ist im Einsatz. Eine Tabelle mit der Kennzeichnung, ob es sich um einen Arbeitstag handelt oder nicht, steht mir zur Verfügung: (Datum / Arbeitstag (J/N))
Vielen Dank für eure Vorschläge!
ich möchte die Dauer eines gesetzten Status berechnen, schaffe das aber leider nicht.
Ein Beispiel der Tabelle ist angehängt.
Ich muss also z.B. berechnen, wie lange der Status "20" gesetzt war. Dies ist für Beleg "A001" vom 05.01.2016 08:05 bis 08.01.2016 08:11 der Fall - soweit auch kein Problem.
Nun sollte ich aber nur die Arbeitszeit (zB 08-17 Uhr) an Arbeitstagen (also ohne SA/SO/Feiertag) für die Berechnung berücksichtigen - und dabei scheitere ich leider.
D.h. das erwünschte Ergebnis wäre "2166 Minuten".
MS SQL Server 2012 ist im Einsatz. Eine Tabelle mit der Kennzeichnung, ob es sich um einen Arbeitstag handelt oder nicht, steht mir zur Verfügung: (Datum / Arbeitstag (J/N))
Vielen Dank für eure Vorschläge!
")