Hallo,
ich kaufe seit ein paar Jahren Aktien im kleinen Stil und habe alle Käufe, Kaufpreis, Dividende,.. jetzt mal in eine Maria DB eingetragen und würde mir das gerne in Power BI Desktop auswerten.
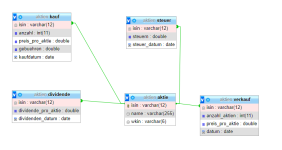
Anbei das DB-Schema. Es geht um die Tabellen "kauf" und "dividende". Aus der Tabelle "aktie" joine ich mir am Ende noch den Namen, aber das ist erstmal egal. ISIN ist jeweils die ID, das ist die "Internationale Wertpapierkennung", die ich als ID verwende, da sie eindeutig ist.
Was will ich nun machen: Ich möchte eine View erstellen, in der ich mir pro Jahr für jede Aktiengesellschaft (also GROUP BY ISIN) und Jahr die Dividende ausrechne. Was es dabei zu beachten gilt ist natürlich, dass, wenn die Dividende z.B. im April 2020 ausgezahlt wird, und ich zu dem Zeitpunkt 20 Aktien dieser AG hatte, im August 2020 weitere 10 Aktien kaufe, dass dann nur 20 Aktien mit der Dividende multipliziert werden. Die 10 anderen Aktien hatte ich ja zum Zeitpunkt der Auszahlung noch nicht.
Eine Einschränkung, bei der ich auch nicht genau weiß, wie es ist, aber für mich auch bisher nie in Frage kam: wie lange ich eine Aktie vor der Hauptversammlung besitzen muss, damit ich dafür Dividende kassiere. Als Annahme setze ich kaufdatum = dividenden_datum.
Folgendes Sql-Statement habe ich mir dafür gebaut:
Der nächste Schritt, der aber technisch schon nicht geht, was am Grouping liegt, ich aber nicht weiß, wie ich das beheben kann, ist die Einschränkung, dass nur die Aktien berücksichtigt werden sollen, die bereits bei der Dividenden-Auszahlung in dem Jahr der Dividende in meinem Besitz waren (fett markiert).
Wäre super, wenn ihr mir helfen und auch etwas erklären könntet, warum es so ist.
Vielen Dank und viele Grüße!
ich kaufe seit ein paar Jahren Aktien im kleinen Stil und habe alle Käufe, Kaufpreis, Dividende,.. jetzt mal in eine Maria DB eingetragen und würde mir das gerne in Power BI Desktop auswerten.
Anbei das DB-Schema. Es geht um die Tabellen "kauf" und "dividende". Aus der Tabelle "aktie" joine ich mir am Ende noch den Namen, aber das ist erstmal egal. ISIN ist jeweils die ID, das ist die "Internationale Wertpapierkennung", die ich als ID verwende, da sie eindeutig ist.
Was will ich nun machen: Ich möchte eine View erstellen, in der ich mir pro Jahr für jede Aktiengesellschaft (also GROUP BY ISIN) und Jahr die Dividende ausrechne. Was es dabei zu beachten gilt ist natürlich, dass, wenn die Dividende z.B. im April 2020 ausgezahlt wird, und ich zu dem Zeitpunkt 20 Aktien dieser AG hatte, im August 2020 weitere 10 Aktien kaufe, dass dann nur 20 Aktien mit der Dividende multipliziert werden. Die 10 anderen Aktien hatte ich ja zum Zeitpunkt der Auszahlung noch nicht.
Eine Einschränkung, bei der ich auch nicht genau weiß, wie es ist, aber für mich auch bisher nie in Frage kam: wie lange ich eine Aktie vor der Hauptversammlung besitzen muss, damit ich dafür Dividende kassiere. Als Annahme setze ich kaufdatum = dividenden_datum.
Folgendes Sql-Statement habe ich mir dafür gebaut:
Das Statement funktioniert, liefert mir aber zu wenige Ergebnisse. Ich erwarte 34 Einträge, die mir über 4 Jahre Dividende eingebracht haben. Bekommen tue ich aber nur 8. Ich würde jetzt ein Ergebnis mit 34 Einträgen erwarten, bei denen ich für alle Aktien, die ich pro AG in einem Jahr hatte, die Dividende sehe.SELECT
YEAR(a.dividenden_datum),
a.isin,
SUM(b.anzahl),
a.dividende_pro_aktie,
SUM(b.anzahl) * a.dividende_pro_aktie as dividende
FROM
dividende a
JOIN
kauf b
ON
a.isin = b.isin
and
YEAR(a.dividenden_datum) = YEAR(b.kaufdatum)
GROUP BY
YEAR(a.dividenden_datum),
a.isin
ORDER BY
YEAR(a.dividenden_datum),
a.isin
Der nächste Schritt, der aber technisch schon nicht geht, was am Grouping liegt, ich aber nicht weiß, wie ich das beheben kann, ist die Einschränkung, dass nur die Aktien berücksichtigt werden sollen, die bereits bei der Dividenden-Auszahlung in dem Jahr der Dividende in meinem Besitz waren (fett markiert).
Ich weiß, ich könnte auch direkt die Beträge speichern, die ich pro Jahr in Aktien investiert und die Dividende. die ich kassiert habe. Das soll aber auch eine Übung sein, etwas tiefer in Sql einzusteigen. Außerdem habe ich k.A., für welche Auswertung ich dies vielleicht mal brauchen kann.SELECT
YEAR(a.dividenden_datum),
a.isin,
SUM(b.anzahl),
a.dividende_pro_aktie,
SUM(b.anzahl) * a.dividende_pro_aktie as dividende
FROM
`dividende` a
JOIN
kauf b
ON
a.isin = b.isin
and
YEAR(a.`dividenden_datum`) = YEAR(b.kaufdatum)
and
a.dividende_datum >= b.kaufdatum
GROUP BY
YEAR(a.dividenden_datum),
a.isin
ORDER BY
YEAR(a.dividenden_datum),
a.isin
Wäre super, wenn ihr mir helfen und auch etwas erklären könntet, warum es so ist.
Vielen Dank und viele Grüße!