JudAD
Fleissiger Benutzer
- Beiträge
- 71
Hallo Zusammen,
leider stehe ich wieder vor einem für mich komplexen Problem
Ich habe folgendes Problem:
Ich würde gerne ein Feld (Kenzeichen) einer Tabelle (Artikel) in Abhängigkeit des Vorkommens der Artikelnummer in einem Feld (Alternativen) einer anderen Tabelle (Material) aktualisieren.
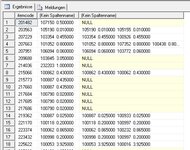
Das Problem ist, dass die Daten im Feld "Alternativen" nicht als einzelne Datensätze, sondern getrennt mit TAB+TAB & CR+LF in einem Datensatz vorliegen (das ist zwar ein völlig idiotisches Datenbankdesign - aber das hab nicht ich verbrochen). Es kommt immer erst die Artikelnummer gefolgt von 2 TAB [sprich CHAR(9)+CHAR(9)] dannach kommt eine Mengenangabe gefolgt von CR+LF [sprich CHAR(13)+CHAR(10)] was das Ende eines Datensazuens markiert. Das kann dann innerhalb eines Datensatzen n-Mal vorkommen. Unten habe ich mal 3 Zeilen des Feldes dargestellt. Hier kann man sehen das es sowohl Datensätze gibt die nur einen Eintrag aus Artikelnummer + Menge haben oder auch im letzten Datensatz 4.
200056 23.550000
100028 23.550000 200056 23.550000
102514 7.800000 109252 7.800000 207283 7.800000 107284 7.800000
Nun würde ich gerne in der Tabelle Artikel das Feld Kennzeichen mit dem Wert "BAUGRUPPE" befüllen wenn die Artikelnummer im Feld Alternativen der Tabelle Material vorkommt und die Artikelnummer mit dem Wert 2 beginnt.
Vereinfacht:
update Artikel set Kennzeichen = 'BAUGRUPPE' where Artikelnummer in (select Alternativen from Material) and LEFT(Artikelnummer,1) = '2'
Dass das so nicht funktioniert ist mir klar - aber ich habe keine Ahnung wie ich das machen kann.
DANKE VORAB!
leider stehe ich wieder vor einem für mich komplexen Problem
Ich habe folgendes Problem:
Ich würde gerne ein Feld (Kenzeichen) einer Tabelle (Artikel) in Abhängigkeit des Vorkommens der Artikelnummer in einem Feld (Alternativen) einer anderen Tabelle (Material) aktualisieren.
Das Problem ist, dass die Daten im Feld "Alternativen" nicht als einzelne Datensätze, sondern getrennt mit TAB+TAB & CR+LF in einem Datensatz vorliegen (das ist zwar ein völlig idiotisches Datenbankdesign - aber das hab nicht ich verbrochen). Es kommt immer erst die Artikelnummer gefolgt von 2 TAB [sprich CHAR(9)+CHAR(9)] dannach kommt eine Mengenangabe gefolgt von CR+LF [sprich CHAR(13)+CHAR(10)] was das Ende eines Datensazuens markiert. Das kann dann innerhalb eines Datensatzen n-Mal vorkommen. Unten habe ich mal 3 Zeilen des Feldes dargestellt. Hier kann man sehen das es sowohl Datensätze gibt die nur einen Eintrag aus Artikelnummer + Menge haben oder auch im letzten Datensatz 4.
200056 23.550000
100028 23.550000 200056 23.550000
102514 7.800000 109252 7.800000 207283 7.800000 107284 7.800000
Nun würde ich gerne in der Tabelle Artikel das Feld Kennzeichen mit dem Wert "BAUGRUPPE" befüllen wenn die Artikelnummer im Feld Alternativen der Tabelle Material vorkommt und die Artikelnummer mit dem Wert 2 beginnt.
Vereinfacht:
update Artikel set Kennzeichen = 'BAUGRUPPE' where Artikelnummer in (select Alternativen from Material) and LEFT(Artikelnummer,1) = '2'
Dass das so nicht funktioniert ist mir klar - aber ich habe keine Ahnung wie ich das machen kann.
DANKE VORAB!