Verwendeter Datenbank-Server: MySQL 8.0 Community Edition
Hallo,
in einer Tabelle werden von diversen Zählern (z.B. Strom- Gas- Wasserzählern) regelmäßig die Stände eingetragen.
Die Tabelle hat folgenden Aufbau:
CREATE TABLE tab_ZaehlerAblese (
ID int NOT NULL AUTO_INCREMENT,
ID_Zaehler int DEFAULT NULL,
Stand decimal(18, 4) DEFAULT NULL,
Ablesedatum datetime DEFAULT NULL,
PRIMARY KEY (ID)
)
ENGINE = INNODB,
AUTO_INCREMENT = 35,
AVG_ROW_LENGTH = 819,
CHARACTER SET utf8mb4,
COLLATE utf8mb4_0900_ai_ci;
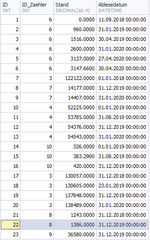
In der Tabelle sind Einträge wie z.B. diese vorhanden:
ZaehlerAbleseDaten.png
Die Tarif-Informationen stehen u.a. in dieser Tabelle:
CREATE TABLE tab_ZaehlerTarifPostenDetails (
ID int NOT NULL AUTO_INCREMENT,
ID_Zaehler int NOT NULL,
StartDatum datetime DEFAULT NULL,
EndDatum datetime DEFAULT NULL,
ZusatzText varchar(510) DEFAULT NULL,
Betrag decimal(15, 5) DEFAULT NULL,
PRIMARY KEY (ID)
)
ENGINE = INNODB,
AUTO_INCREMENT = 23,
AVG_ROW_LENGTH = 1365,
CHARACTER SET utf8mb4,
COLLATE utf8mb4_0900_ai_ci;
Über das Feld ID_Zaehler sind die beiden Tabellen verbunden.
Die Tarif-Gültigkeit wird mit den Angaben in den Feldern StartDatum und EndDatum begrenzt. Das StartDatum ist immer angegeben; das EndDatum kann auch Null-Werte enthalten, falls der Tarif kein EndDatum aufweist.
Zu meinem Anliegen:
Ich stehe nun etwas auf dem Schlauch, da mir nicht einfällt, wie man die Verbrauchswerte für die einzelnen Ablese-Zeiten ermitteln kann, für die passende Tarife (Tabelle: tab_ZaehlerTarifPostenDetails) existieren.
Hat da jemand eine Idee?
Hallo,
in einer Tabelle werden von diversen Zählern (z.B. Strom- Gas- Wasserzählern) regelmäßig die Stände eingetragen.
Die Tabelle hat folgenden Aufbau:
CREATE TABLE tab_ZaehlerAblese (
ID int NOT NULL AUTO_INCREMENT,
ID_Zaehler int DEFAULT NULL,
Stand decimal(18, 4) DEFAULT NULL,
Ablesedatum datetime DEFAULT NULL,
PRIMARY KEY (ID)
)
ENGINE = INNODB,
AUTO_INCREMENT = 35,
AVG_ROW_LENGTH = 819,
CHARACTER SET utf8mb4,
COLLATE utf8mb4_0900_ai_ci;
In der Tabelle sind Einträge wie z.B. diese vorhanden:
ZaehlerAbleseDaten.png
Die Tarif-Informationen stehen u.a. in dieser Tabelle:
CREATE TABLE tab_ZaehlerTarifPostenDetails (
ID int NOT NULL AUTO_INCREMENT,
ID_Zaehler int NOT NULL,
StartDatum datetime DEFAULT NULL,
EndDatum datetime DEFAULT NULL,
ZusatzText varchar(510) DEFAULT NULL,
Betrag decimal(15, 5) DEFAULT NULL,
PRIMARY KEY (ID)
)
ENGINE = INNODB,
AUTO_INCREMENT = 23,
AVG_ROW_LENGTH = 1365,
CHARACTER SET utf8mb4,
COLLATE utf8mb4_0900_ai_ci;
Über das Feld ID_Zaehler sind die beiden Tabellen verbunden.
Die Tarif-Gültigkeit wird mit den Angaben in den Feldern StartDatum und EndDatum begrenzt. Das StartDatum ist immer angegeben; das EndDatum kann auch Null-Werte enthalten, falls der Tarif kein EndDatum aufweist.
Zu meinem Anliegen:
Ich stehe nun etwas auf dem Schlauch, da mir nicht einfällt, wie man die Verbrauchswerte für die einzelnen Ablese-Zeiten ermitteln kann, für die passende Tarife (Tabelle: tab_ZaehlerTarifPostenDetails) existieren.
Hat da jemand eine Idee?