Wie plant man geschickt eine Datenbank?
Nehmen wir mal an, wir haben 20 Fütterungsautomanten, in denen Haus- und Wildtiere gefüttert werden. Die Fütterungsautomaten bekommen die Namen F1, F2 ... F20. Der Datensatz in allen Fütterungsautomaten ist identisch
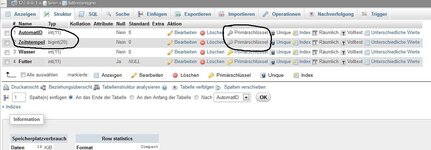
Zeitstempel, Futtermenge, Wassermenge
Die Futterautomaten geben Wasser und Futter stets zum gleichen Zeitpunkt ab, sagen wir mal zu jeder vollen Stunde. Jeder Futterautomat sendet getrennt vom anderen Automaten seine Daten an die Datenbank, die Zeitstempel sind also pro Intervall identisch.
Wie plant man jetzt geschickt die Tabellen mit Spalten?
In der späteren Auswertungen möchte ich z.B. sehen, wann zu welcher Uhrzeit wie viel Wasser und wieviel Futter jeder Automat ausgegeben hat und ich will auch Summen von einzelnen Gruppen bilden könnnen oder auch die Gesamtmengen aller Automaten.
Variante 1:
Jetzt könnte ich für jeden Futterautomaten eine eigene Tabelle erstellen mit den drei Spalten
Zeitstempel, Futtermenge, Wassermenge
Variante 2: Eine Tabelle mit vielen Spalten:
Zeitstempel, Futtermenge F1, Wassermenge F2, Futtermenge F2, Wassermenge F2...
Vorteil Variante 1:
Ich kann schnell die Werte in die Tabellen schreiben. Jeder Futterautomat sendet seine Daten unabhängig an den Server. Ich brauch nicht darauf achten, ob eine Zeile mit dem Zeitstempel schon vorhanden ist und dann die Tabellenwerte des fehlenden Automaten anfüngen.
Bei Variante 2 muss ich prüfen, ob bereits ein Zeitstempel schon vorhanden ist und dann die Spaltenwerte an den Stellen ergänzen.
Vorteil Variante 2:
Für die spätere Auswertung habe ich nun bereits alle Spaltenwerte in einer Tabelle zusammengefasst. Möchte ich Werte aus dem Beispiel der Variante 1 erzeugen, dann muss ich erst die Werte aus den einzelnen Tabellen in einer Tabelle zusmmenfassen.
Außerdem wird hier etwas Speicherplatz gespart. Der Zeitstempel wird nur einmal gespeichert, bei 20 Einzeltabellen 20mal.
Irgendwie hat jede der beiden Varianten ihre Vor- und Nachteile. Gibt es noch weitere Möglichkeiten für dieses Modellbeispiel?
Nehmen wir mal an, wir haben 20 Fütterungsautomanten, in denen Haus- und Wildtiere gefüttert werden. Die Fütterungsautomaten bekommen die Namen F1, F2 ... F20. Der Datensatz in allen Fütterungsautomaten ist identisch
Zeitstempel, Futtermenge, Wassermenge
Die Futterautomaten geben Wasser und Futter stets zum gleichen Zeitpunkt ab, sagen wir mal zu jeder vollen Stunde. Jeder Futterautomat sendet getrennt vom anderen Automaten seine Daten an die Datenbank, die Zeitstempel sind also pro Intervall identisch.
Wie plant man jetzt geschickt die Tabellen mit Spalten?
In der späteren Auswertungen möchte ich z.B. sehen, wann zu welcher Uhrzeit wie viel Wasser und wieviel Futter jeder Automat ausgegeben hat und ich will auch Summen von einzelnen Gruppen bilden könnnen oder auch die Gesamtmengen aller Automaten.
Variante 1:
Jetzt könnte ich für jeden Futterautomaten eine eigene Tabelle erstellen mit den drei Spalten
Zeitstempel, Futtermenge, Wassermenge
Variante 2: Eine Tabelle mit vielen Spalten:
Zeitstempel, Futtermenge F1, Wassermenge F2, Futtermenge F2, Wassermenge F2...
Vorteil Variante 1:
Ich kann schnell die Werte in die Tabellen schreiben. Jeder Futterautomat sendet seine Daten unabhängig an den Server. Ich brauch nicht darauf achten, ob eine Zeile mit dem Zeitstempel schon vorhanden ist und dann die Tabellenwerte des fehlenden Automaten anfüngen.
Bei Variante 2 muss ich prüfen, ob bereits ein Zeitstempel schon vorhanden ist und dann die Spaltenwerte an den Stellen ergänzen.
Vorteil Variante 2:
Für die spätere Auswertung habe ich nun bereits alle Spaltenwerte in einer Tabelle zusammengefasst. Möchte ich Werte aus dem Beispiel der Variante 1 erzeugen, dann muss ich erst die Werte aus den einzelnen Tabellen in einer Tabelle zusmmenfassen.
Außerdem wird hier etwas Speicherplatz gespart. Der Zeitstempel wird nur einmal gespeichert, bei 20 Einzeltabellen 20mal.
Irgendwie hat jede der beiden Varianten ihre Vor- und Nachteile. Gibt es noch weitere Möglichkeiten für dieses Modellbeispiel?
")