verkruemelt
Benutzer
- Beiträge
- 6
Hallo zusammen,
ich soll eine Webanwendung schreiben, bei der Mitarbeiter bestimmte Werte eintragen sollen, diese Werte werden dann für Auswertungen benötigt.
Dabei gibt es folgendes zu beachten:
Die Ideallösung sähe so aus, die Teams und die Werte über die Webseite anpassen zu können, ohne dafür manuell in der DB etwas ändern zu müssen.
Oder gibt es für so etwas vielleicht schon etwas fertiges?
ich soll eine Webanwendung schreiben, bei der Mitarbeiter bestimmte Werte eintragen sollen, diese Werte werden dann für Auswertungen benötigt.
Dabei gibt es folgendes zu beachten:
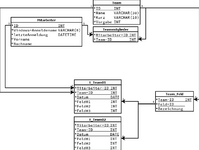
- ein Mitarbeiter kann in einem oder mehreren Teams sein
- pro Team, Tag und Mitarbeiter gibt es einen Eintrag mit entsprechenden Werten
- ein Mitarbeiter kann in einem anderen Team eingesetzt werden (zu einem neuen Monat)
- die Werte unterscheiden sich von Team zu Team (ein paar Werte sind gleich)
- es können Werte für ein Team entfallen
- es können neue Werte für ein Team benötigt werden
- es können Teams entfallen
- es können neue Teams entstehen
Die Ideallösung sähe so aus, die Teams und die Werte über die Webseite anpassen zu können, ohne dafür manuell in der DB etwas ändern zu müssen.
Oder gibt es für so etwas vielleicht schon etwas fertiges?