Hallo!
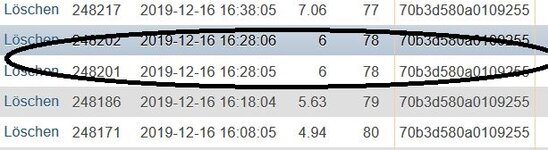
Ich habe eine Tabelle "lorawan", wo ich Temperaturwerte von einem Funkempfänger, welcher mir die Werte der Temperatursensoren empfängt, alle 10 Minuten speichere. (1 Wert ca. alle 10 Minuten +/- einige Sekunden)
Die Tabelle hat folgenden Aufbau:
ID | DATE| TEMP | DEVEUI
"Date" ist ein Timestamp im Format 2019-12-08 09:44:41
"DEVEUI" ist die Seriennummer des Sensors, nach der ich bei der Abfrage Suche. Es gibt 2 Sensoren, die in die Tabelle "lorawan" schreiben.
Jetzt ist es so, dass ich manchmal doppelte Einträge habe, die max. 5 Sekunden auseinander liegen. Diese möchte ich finden, und jeweils einen davon löschen. Die Einträge kommen daher, dass die Sensoren an mehrere Empfangsstationen senden, und diese dann die Einträge doppelt speichern, wenn sie mehr als 500ms auseinander liegen. Die Zeitverschiebung von bis zu 5 Sekunden ist mit der Laufzeit zu begründen.
Welches Statement benötige ich, um die doppelten Einträge zu entferne?
liebe Grüße,
Markus
Ich habe eine Tabelle "lorawan", wo ich Temperaturwerte von einem Funkempfänger, welcher mir die Werte der Temperatursensoren empfängt, alle 10 Minuten speichere. (1 Wert ca. alle 10 Minuten +/- einige Sekunden)
Die Tabelle hat folgenden Aufbau:
ID | DATE| TEMP | DEVEUI
"Date" ist ein Timestamp im Format 2019-12-08 09:44:41
"DEVEUI" ist die Seriennummer des Sensors, nach der ich bei der Abfrage Suche. Es gibt 2 Sensoren, die in die Tabelle "lorawan" schreiben.
Jetzt ist es so, dass ich manchmal doppelte Einträge habe, die max. 5 Sekunden auseinander liegen. Diese möchte ich finden, und jeweils einen davon löschen. Die Einträge kommen daher, dass die Sensoren an mehrere Empfangsstationen senden, und diese dann die Einträge doppelt speichern, wenn sie mehr als 500ms auseinander liegen. Die Zeitverschiebung von bis zu 5 Sekunden ist mit der Laufzeit zu begründen.
Welches Statement benötige ich, um die doppelten Einträge zu entferne?
liebe Grüße,
Markus